Analyzing US Media Blocking of EU Visitors
I have been working and studying technology for over 10 years now, and the one thing I really love is discovering weird technical quirks you can find on Internet, and what they tell us about society. Things like how bad geolocation of IP addresses turned the life of a Kansas family into hell or how to track dictator’s aircraft from open flight information.
Among them, I discovered last year that the HTTP code HTTP 451 Unavailable For Legal Reasons was actually used by some US media to block European visitors as they do not want to comply with GDPR regulation. The code 451 is actually a reference to Ray Bradbury’s book Fahrenheit 451.
Cat version of HTTP code 451, because Internet
I wondered how many media in the US are actually implementing restrictions for EU visitors due to GDPR and how many of them actually use HTTP 451 for that purpose. Here is a quick summary of what I found and how I found it.
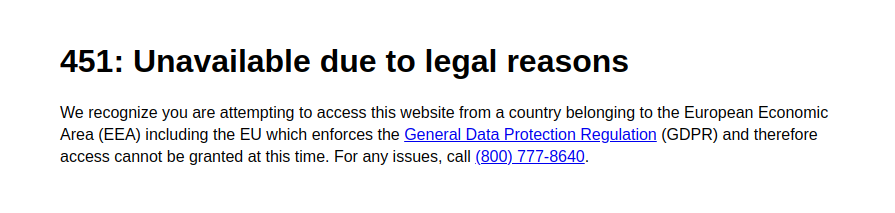
GDPR Obligations#
The General Data Protection Regulation (GDPR) is a European regulation on privacy that came into effect in 2018. Among other restrictions, it requires to have informed consent from users to access their data and to detail how data are being handled by a website. It clearly makes online tracking for advertisement harder, so several US media companies decided it was not worth the effort and started blocking European visitors.
Finding a list of US media#
The first step needed was to find a list of US media websites. I know two main resources to get a list of US media, the first one is the old ABYZ News Link website that gathers lists of media from different countries. For the US, it classifies them as national and regional media. I don’t know how updated this website is, but it has tens of thousands of media sources, so it is a good list to have. The second one is the amazing MediaCloud project made by a consortium of US institutions. It allows downloading US national and US State & Local media from their Source Manager.
I wrote a basic python scraper for ABYZ News Link and downloaded the lists from MediaCloud Source Manager. When we merge these two lists and do some cleaning, we have 266 national media and 9772 regional media.
Checking HTTP answers#
We can easily write a python script that takes a list of domains as input, do an http / https request to them, and check the HTTP result code. After some manual testing, I realized that several websites are also blocking EU visitors with 200 HTTP code and specific error messages such as “We are currently unavailable in your region” or “our website is currently unavailable in most European countries”, so I have also added a few checks for these text in webpages. This check is not totally reliable as some websites can have a custom blocking page that does not use these sentences but it seems good enough to catch many of them.

Here is the python script:
def detect_gdpr_block(res):
"""
Detect if the page is blocked due to GDPR
returns True if it is blocked
"""
if r.status_code == 451:
return "Yes"
elif r.status_code == 200:
if "We are currently unavailable in your region" in r.text:
return "Yes"
if "our website is currently unavailable in most European countries" in r.text:
return "Yes"
elif r.status_code == 403:
if "You don't have permission to access" in r.text:
return "Yes"
return "No"
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Scans domains looking for HTTP 451 which is GDPR restrictions')
parser.add_argument('DOMAINS', help="Files listing domains")
parser.add_argument('--output', '-o', help="Output file", default="output.csv")
args = parser.parse_args()
# Important to have a clean UA bc some websites block requests UA
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'}
with open(args.DOMAINS, 'r') as f:
sites = f.read().split('\n')
fout = open(args.output, 'a+')
csvout = csv.writer(fout, delimiter=",", quotechar='"')
csvout.writerow(["Domain", "Accessible", "url", "Status Code", "Redirect to another domain", "HTML Size", "GDPR blocking"])
for site in sites:
if site.strip() == '':
continue
print("Domain: {}".format(site.strip()))
if site.startswith('http'):
url = site
else:
url = "http://{}/".format(site)
try:
r = requests.get(url, headers=headers, timeout=15)
except (requests.exceptions.ConnectionError, requests.exceptions.TooManyRedirects, requests.exceptions.ReadTimeout, urllib3.exceptions.LocationParseError):
csvout.writerow([site, "No", url, "", "", "", ""])
print("Not accessible")
except UnicodeError:
csvout.writerow([site, "No", url, "", "", "", ""])
print("Bug with the URL")
else:
if site in r.url:
redir = "No"
else:
redir = "Yes"
gdpr = detect_gdpr_block(r)
print("Status code: {} / redirect {} / GDPR blocked {}".format(r.status_code, redir, gdpr))
csvout.writerow([site, "Yes", r.url, r.status_code, redir, len(r.text), gdpr])
Results#
To have an accurate view of how common it is, I have removed from these results all the domains that did not resolve, giving us a total of 248 National media and 9042 regional and state media.
| Total | Blocked | Blocked with HTTP 451 | |
|---|---|---|---|
| US National | 248 | 12 (4.8%) | 6 (2.4%) |
| US Regional | 9042 | 1343 (14.8%) | 1269 (14%) |
| Total | 9290 | 1355 (14.6%) | 1275 (13.7%) |
So almost 15% of US websites are blocking European visitors, including several national media like the Baltimore Sun or BuffaloNews. Overall, HTTP Code 451 is the main way to answer when blocking visitors from Europe. I am not sure Ray Bradbury would have appreciated the irony of blocking access to knowledge with a reference to his book.
You can find the data and source code used in this article on github.
This blog post was written while listening to Beethoven Sonata n°23 “Appassionata”